
1. 근황
2024년 4월 10일, 전역 후 후련할 것만 같았던 마음은 좀처럼 편하지 못했다. 🥲 1년 9개월이라는 시간을 군대에서보내는 동안안 정말 많은 것이 눈에 띄게 바뀌었다! 챗GPT의 등장, 저출산, 경기 침체, 친구들의 취직등등…. 비록록 대학교 2학년이라는 시기가 취업과 장래를 생각하기에는 이른 시기라고 생각하곤 했지만, 그렇다고 무턱대고 놀기에는 나의 20대가가 너무 아깝다는 생각이 들었다. 🔥🔥 (카뮈의 철학이 머릿속에 떠오르던 시기였다!!)
'뭐라도 해보자! 좋아하는 일, 하고 싶은 일을 하염없이 찾기보다 당장 뭐라도 해보는 거야!' 20대의 가장 큰 자산은 '경험'이라는 생각으로 살던 저는 본격적으로 뭐라도 해보기 시작했다. 그러던 와중 컴퓨터공학과에 재학 중인 나는 당시 스타트업에서 인턴 생활을 하는 여자 친구의 영향으로 개발에 큰 관심을 가지게 된다. 당시 4월부터 시작하는 카카오에서 운영하는 부트캠프인 카카오테크 캠퍼스에 BE 트랙으로 지원하여 합격한 상태이기에 시작이 좋았다!
우선 대략 2달 동안 '할 수 있는 것들'에 매진하였다. 카테캠(카카오테크 캠퍼스) 강의를 꾸준히 들으며 복습을 게을리하지 않았고, 1학년 때부터 재미를 붙인 알고리즘을 꾸준히 풀며 블로그에 풀이를 올렸다. 또한 동아리를 통해 'Spring 입문초록스터디'에 참여하였으며 부족한 부분은 인프런의의 김영한 강사님 강의로 채워나갔다. 꾸준히 공부하는 것이 지겹고 싫다기보다는 내가 할 수 있는 것들을 하면서성장해 나가는는 내 모습이 되게 재밌었다! RPG 게임처럼 명확한 레벨은 보이지 않지만 적어도 어제와 오늘의 나는 정말 다르다는 것을 매일 느끼며 큰 보람을 느꼈다. 특히 여자 친구와와 학교 선배님을 만나며 공부하며 궁금했던 것을 물어보고 부족했던 내용을 채우는 과정에서 한 달 전, 아니 일주일 전만 해도 무지했던 내용들이 머릿속에서 정리되는 경험이 내겐 큰 성취감이자 꾸준히 할 수 있게 해준 원동력이었다.
2달이 지나고 6월 초쯤 되니 내가 배웠던 내용들을 직접 구현해보고 싶었다. 나와 같은 마음을 가진 4명(같은 학번 친구 2명 + 여자친구와 여자친구의 친구)과 함께 팀을 꾸려 '경단' 프로젝트를 진행하게 된다. 처음엔 우리끼리 재밌는 주제의 토이 프로젝트를 만들어보자는 생각이었지만 목표가 있으면 좋을 거 같아 지원했던 '2024년 SW 중심대학 디지털 경진대회'의 SW부문에 우리 프로젝트 기획서가 채택되어 학교 대표팀으로 참가하게 되었다. 간단한 토이 프로젝트로 끝날줄 알았는데 갑작스러운 기회에 걱정되긴 했다. 왜냐하면 나와 내 친구 2명은 스타트업에서 6개월동안 인턴을 한 여자친구에 비하면 개발 경험이나 프로젝트 경험이 암담한 수준이었기 때문이다. 그래도 하고자 하면 무엇이든 이루어 낼 수 있을 거라는 마음으로 프로젝트에 임하게 된다!!
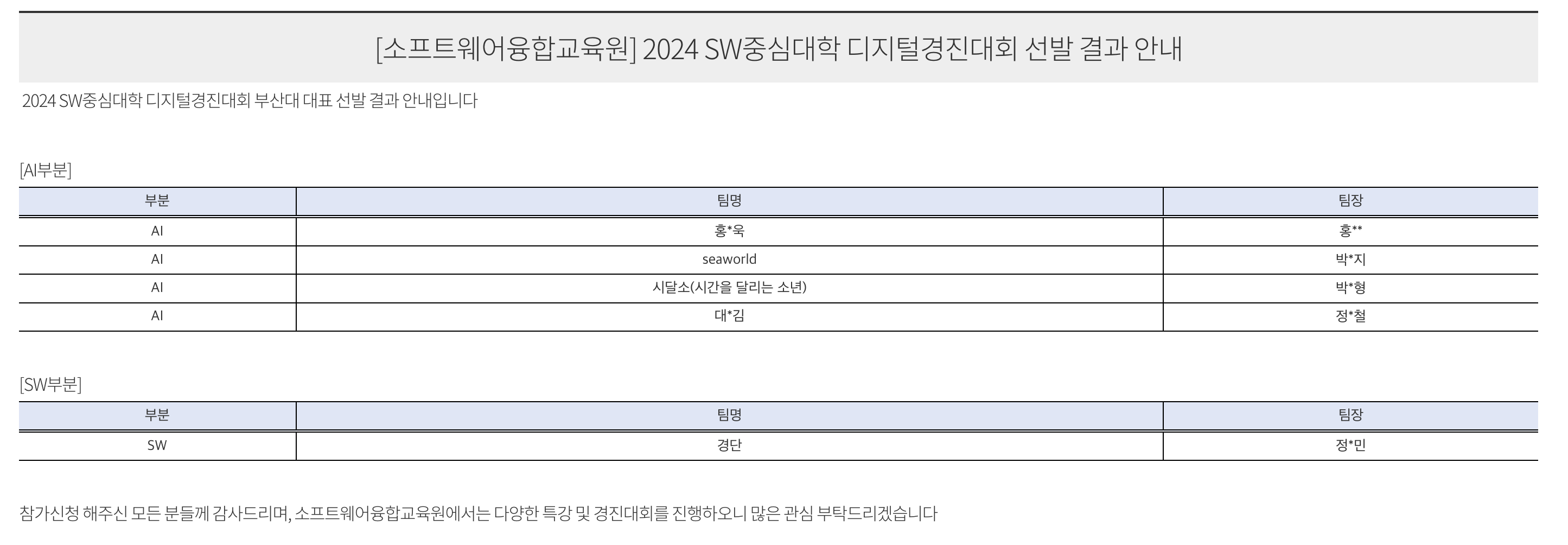
2. 경단 프로젝트 팀원으로서의 내가 한 일들
개발 경험과 프로젝트 경험이 부족했기에 처음엔 팀원으로서 1인분을 할 수 있을지 걱정되었다. 그러나 누구에게나 처음이 있고 내게 이 처음은 가장 값진 것이었으면 좋겠다는 생각 들었다. 우선, 전역 직후 나의 모습과 마찬가지로 '할 수 있는 것들'에 매진하였다.
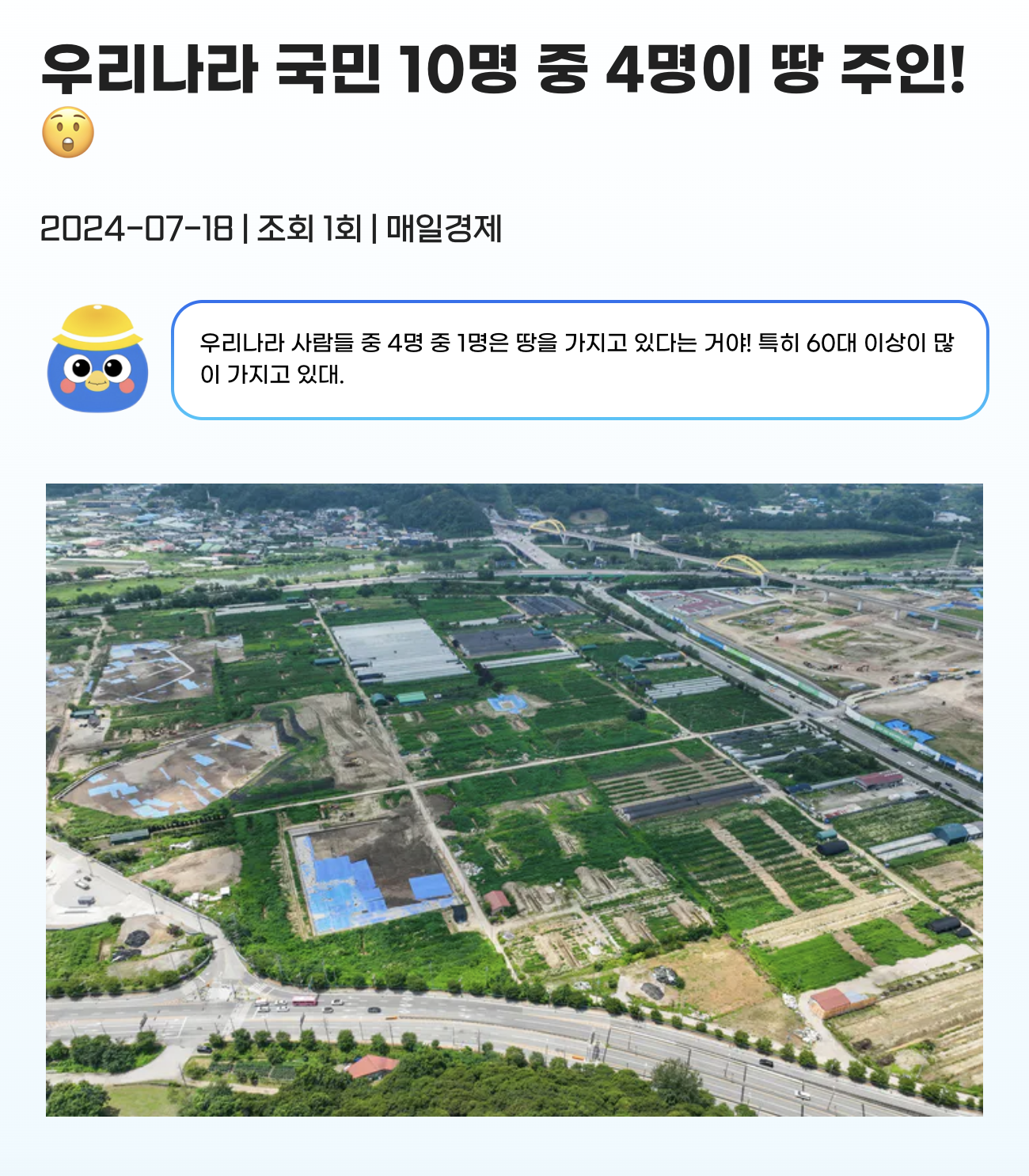
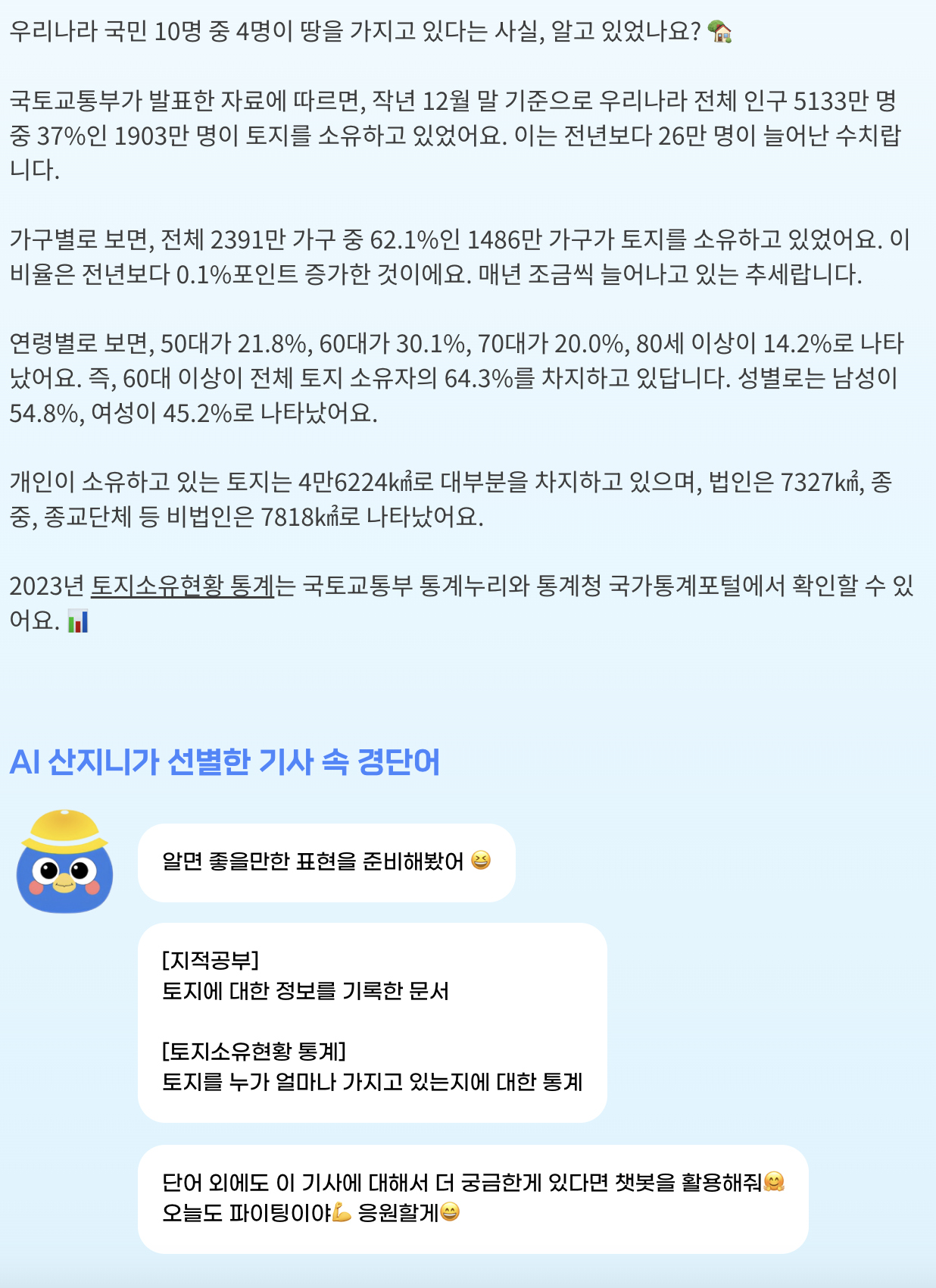
경단 프로젝트의 배경은 '경제를 단순하게'라는 슬로건을 걸고 청년들의 경제적 취약점을 보완하여 경제 문맹률을 낮추자는 것이다. 성인이 되고 본격적인 경제생활을 시작하게 된다. 하지만 아래 기사 자료에서도 볼 수 있듯이 학창 시절 경제는 필수과목이 아니었기에 대다수는 경제 및 금융 관념에 대해 무지하다.

사탐에 경제 과목이 있다 한들 어려운 난이도에 응시율도 낮고 공통 과목 중에서는 경제 관련 수업은 통합사회의 '경제 및 금융' 단원뿐이다.
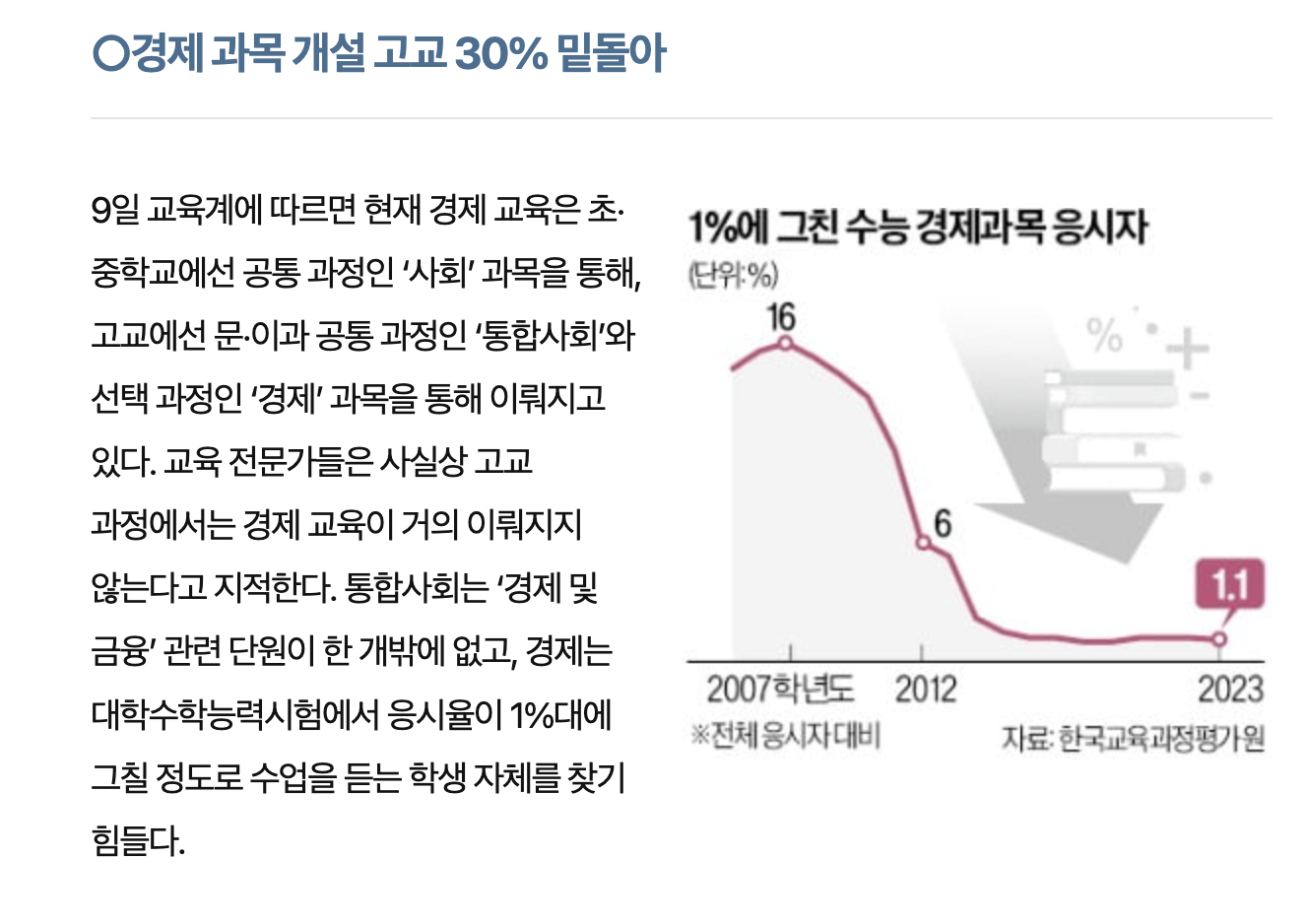
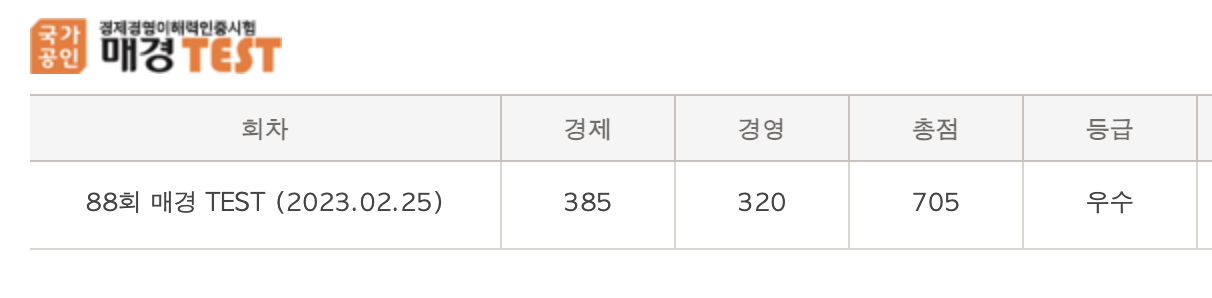
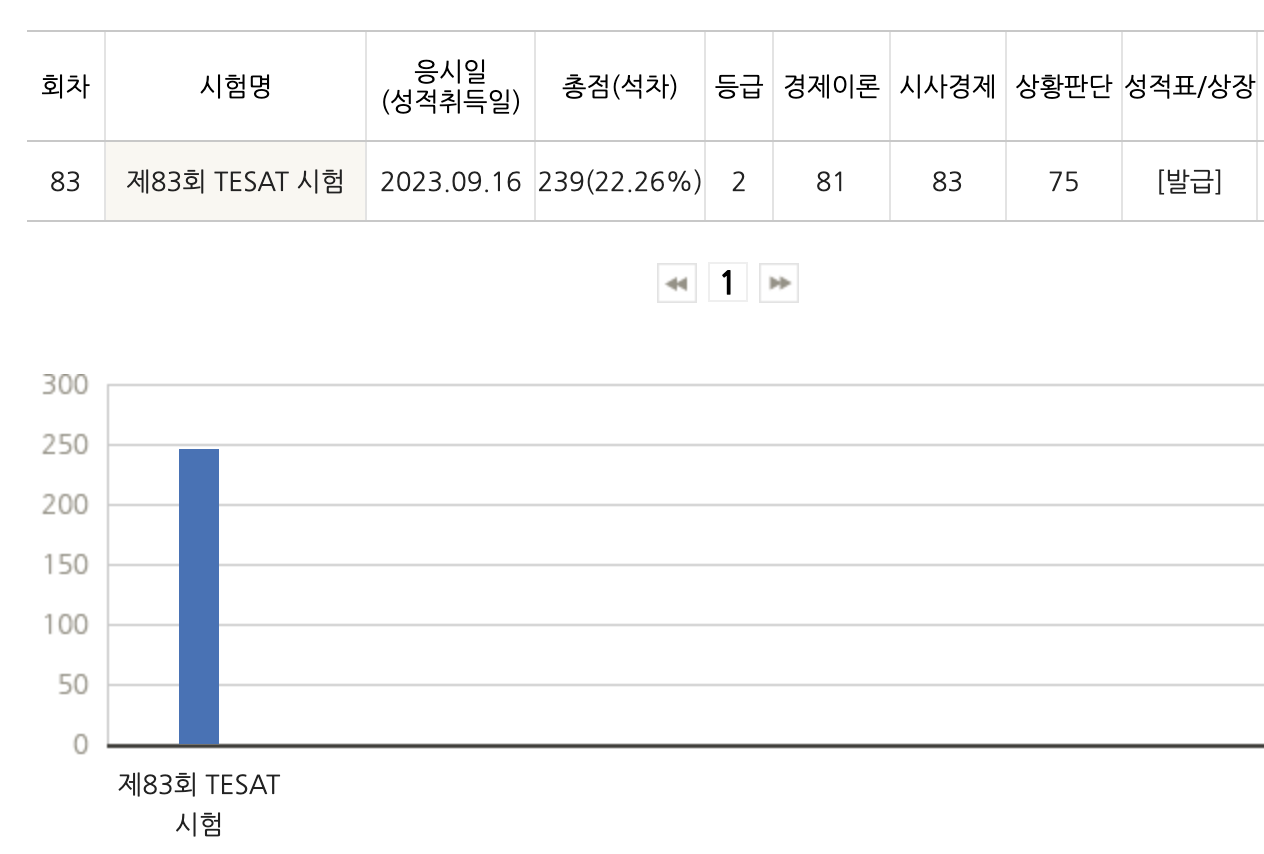
좋아! 청년들의 경제 문맹을 퇴치하는 것은 좋은데 어떤 방법으로…?? 필자는 군복무 시절부터 '어피티'라는 뉴스레터 사이트를 애용하였다. 최신 소식을 쉽게 설명해 주고 어려운 경제 용어 또한 따로 정리해 주기에 전문가가 아닌 나 또한 자연스럽게 경제 이슈에 큰 관심을 가지게 되었고, 국가 공인 경제 자격증인 '매경테스트'와 'TESAT'도 딸 정도로 흥미가 생겼다.
내게 직접적으로 도움이 된 '어피티'에서 영감을 받아 생성형 AI를 활용하여 어려운 경제 기사를 쉽게 설명하면 좋겠다는 생각이 들었다. 팀원들과 주에 3~4번 비대면 혹은 대면으로 만나서 기획하며 경제 기사 플랫폼을 만들기로 결정하였다. 아래 보이는 것처럼 크게 5가지 기능을 기획하였는데, 그중에서 난 어려운 경제 기사를 재생성과 챗봇, 그리고 조회 API를 담당하였다.

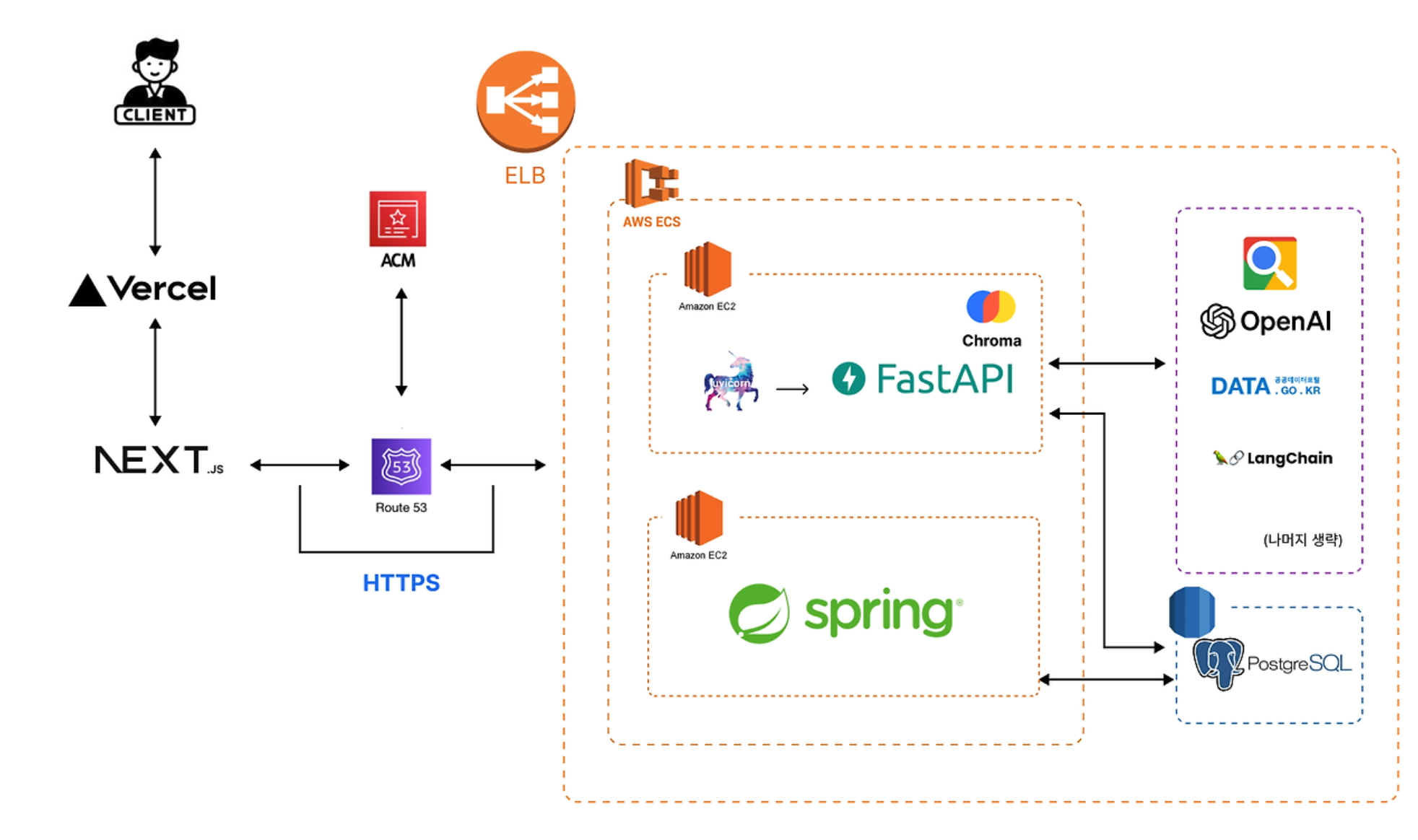
(1) 어려운 경제를 쉬운 기사로 재생성하기
어피티나 뉴닉과 같이 경제 전문가가 아니더라도 읽기 쉬운 뉴스레터들이 있지만 매일경제, 한국경제는 상대적으로 경제 관련 지식이 부족하면 읽기 힘든 부분이 있다. 그렇지만 매일경제와 한국경제는 어피티나 뉴닉보다 최신 이슈에 관해서 더욱 다방면으로 다루고 기사 업로드 속도 또한 훨씬 빠르다. 따라서 장점들만 뽑아 매일경제, 한국경제의 최신 경제 기사를 어피티, 뉴닉과 같이 쉬운 기사로 재생성하는 것이 우리의 목표였다.
우선 FASTAPI를 활용하여 pipenv 기반 환경에서 파이썬 웹스크래핑 라이브러리 'beautiful soup4'를 활용하여 기사 제목, 내용, 이미지를 스크래핑하였다. 그 후 open ai의 gpt-4o 모델을 활용하여 쉬운 기사로 재생성하였다.
async def crawl_article(self, news_type: str, url: str) -> ArticleResponse:
news_type = find_publisher(news_type)
# 웹 페이지 가져오기
try:
response_text = await self.__fetch_page(url)
except aiohttp.ClientError as e:
raise HTTPException(
status_code=400, detail=f"Error fetching the URL: {str(e)}"
) from e
result_html = BeautifulSoup(response_text, "html.parser")
title = self.__find_title(result_html, news_type)
pub_date = self.__find_pub_date(result_html, news_type)
image_url = self.__find_image(result_html, news_type)
if news_type == Publisher.SEOUL_KYUNG:
content = self.__find_content_from_script(result_html)
else:
main_section = self.__find_main_section(result_html, news_type)
content = self.__find_content_from_main_section(main_section, news_type)
if not content.strip():
raise HTTPException(status_code=404, detail="파싱 결과가 없습니다.")
return ArticleResponse(title=title, content=content, pub_date=pub_date, image_url=image_url)
웹 스크래핑의 경우 1학년 때 '노마드코더의 python으로 웹 스크래퍼 만들기' 강의를 수강하고 코로나 확진자 수, 신규 확진자 수 등을 불러와 파일에 저장하는 토이 프로젝트를 홀로 진행한 적이 있었기에 어렵지 않게 구현할 수 있었다. (1학년 때 한 웹 스캐래핑 토이 프로젝트)
gpt를 활용하는 것 또한 open ai playgorund의 API reference에 자세히 정리되어 있어 프롬프팅 엔지니어링 또한 어렵지 않게 구현하였다.
너는 내가 제공하는 어려운 대한민국 경제 신문 본문을 20대 초반이 읽어도 이해하기 쉽게, 한국어로 기사를 재생성하는 기자이다.
아래 json 형식에 맞게 기사를 재생성해야 한다. 단, 기사 본문의 경우 문단을 나누어야 한다.
다음은 json 형식의 예시이다:
{
"title": "기사 제목(한국어)",
"content": "기사 본문 (한국어)",
"phrase": ["어려웠던 경제 표현들" : "어려웠던 경제 표현들을 쉽게 바꾼 문구"] (문자열 리스트) 예를 들어 "환율" : "다른 나라 돈과 우리나라 돈을 교환하는 비율"과 같이,
"comment": "기사를 3줄 이하로 요약하기. 단, 친근하게. (한국어)",
"category": "기사가 어느 카테고리, 즉 enum에 속하는지 (한국어)"
}
enum Category:
ECONOMY_AND_BUSINESS = "경제 및 기업"
POLITICS_AND_SOCIETY = "정치 및 사회"
TECHNOLOGY_AND_CULTURE = "기술 및 문화"
SPORTS_AND_LEISURE = "스포츠 및 여가"
OPINION_AND_ANALYSIS = "오피니언 및 분석"
이후 팀장인 여자친구가 gpt에만 의존하지 않기 위해 RAG / LangChain을 활용하여 재생성하려는 기사와 연관된 내용의 다른 기사들을 불러와 기술적 차별화를 이루었고 매일 오전 5시에 기사를 스크래핑해오는, 스케쥴링 또한 구현하였다.
(2) 대화형 인터페이스 - 챗봇
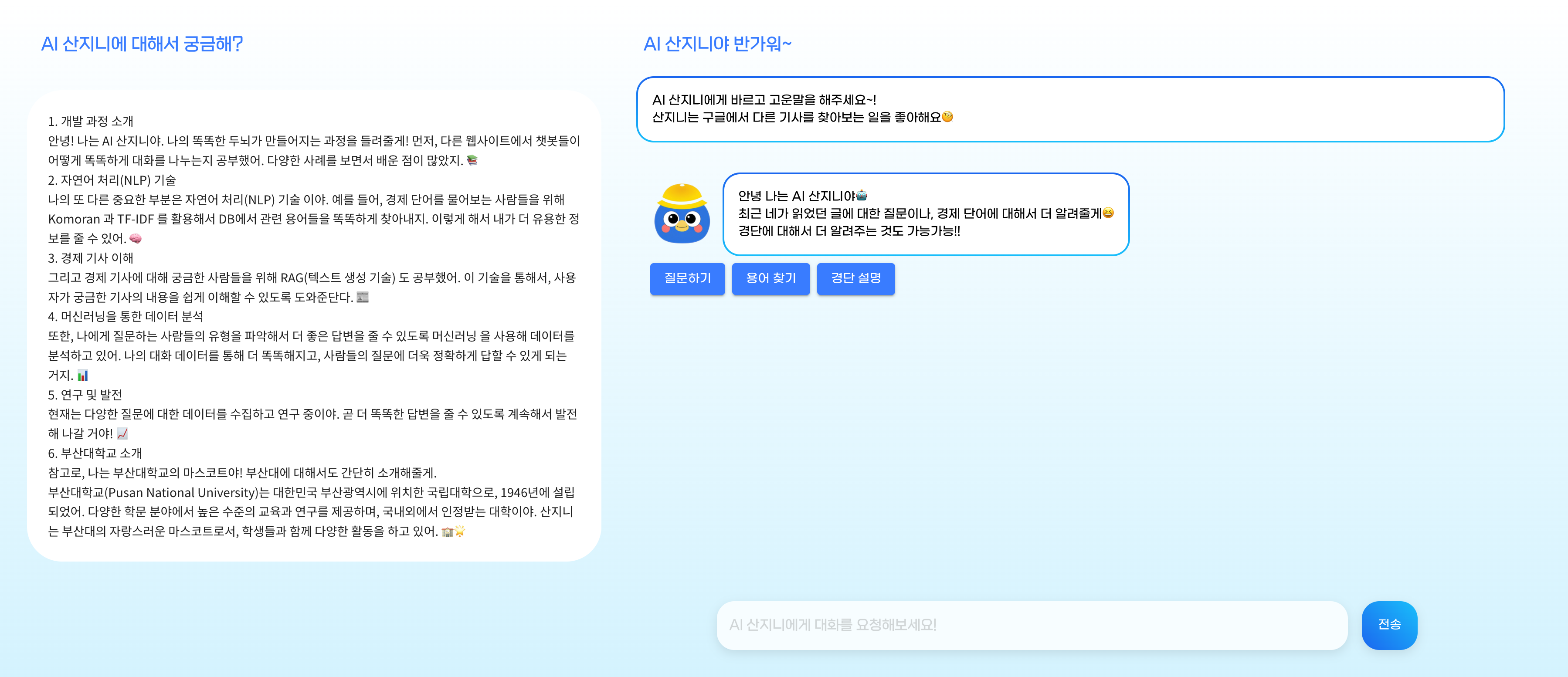
경단을 이용하며 생긴 궁금증들을 다른 웹사이트를 통해 해결하는 것이 아닌 경단 내에서 해결하는 것이 충성 고객 유치와 사용자들의 편의에 있어서 큰 도움이 될 거 같아 대화형 인터페이스인 챗봇을 구현하기로 하였다. 앞서 구현했던 쉬운 기사 재생성과 달리 챗봇 관련 API 모두를 스프링 환경에서 혼자 구현해야 했기에 부담이 있었지만 우려와는 달리 멋지게 해낼 수 있었다!
우선, 챗봇을 사용하는 사용자들은 챗봇을 사용하며 어떤 편의를 기대할지 고민해 보았고 크게 3가지로 추렸다.
첫 번째로 경제 용어를 묻는 상황에 대한 대처가 필요할 거 같았다. 나 또한 경제 기사를 읽으며 어려운 경제 용어들을 한국은행의 경제 용어사전에서 직접 찾아보며 학습했던 경험이 있었기 때문이다. 보통 "GDP가 무엇인지 알려줘"와 같은 질문이 챗봇 대화창에 입력될 텐데 사용자의 질문에 대한 응답을 GPT에 의존하여 처리하기에는 기술적 차별점도 부족하였고 무엇보다 GPT 사용료가 너무 아까웠다! 따라서 GPT 없이 사용자의 질문에 대처하기로 하였다.
일단, 한국은행 경제 용어 700선과 기획재정부의 시사 경제 용어사전을 참고하여 경제 용어의 뜻과 예문을 DB에 저장하였다. 그러나 해당 자료들에서 역시 용어 뜻을 풀이하는 데 있어서 어려운 개념이 빈번하게 사용되었기에 사용자의 이해를 돕고자 용어 뜻과 예문을, GPT를 활용하여 프롬프팅한 뒤에, DB에 저장하였다. 이 과정에서 경제 용어 뜻과 예문을 일일이 DB에 저장하는 것은 무리였기에 JSON 파일에 전부 담은 후 파싱하여 DB에 손쉽게 DB에 저장할 수 있었다. 응답해 주는 과정에서 exception을 방지하고자 단어의 중복 검사 또한 진행해 주었다. 이를 통해 대략 900개가 넘는 경제 용어를 DB에 저장하였다.
{
"term": "STRIPS",
"description": "원금이자분리채권(STRIPS)은 채권의 원금과 이자를 분리하여 각각 개별적인 제로 쿠폰 채권으로 거래하는 금융 상품을 의미합니다.",
"example": "예를 들어, 한 채권의 원금 부분과 이자 부분을 따로 분리하여 각각 거래할 수 있습니다."
},
{
"term": "원금이자분리채권",
"description": "원금이자분리채권(STRIPS)은 채권의 원금과 이자를 분리하여 각각 개별적인 제로 쿠폰 채권으로 거래하는 금융 상품을 의미합니다.",
"example": "예를 들어, 한 채권의 원금 부분과 이자 부분을 따로 분리하여 각각 거래할 수 있습니다."
},
{
"term": "위험가중자산",
"description": "위험가중자산은 은행이 보유한 자산 중에서 위험도를 반영하여 가중치를 부여한 자산을 의미합니다. 이는 자본 적정성을 평가하는 데 사용됩니다.",
"example": "예를 들어, 주택담보대출은 상대적으로 낮은 가중치를 가지지만, 무담보 대출은 높은 가중치를 가질 수 있습니다."
},
{
"term": "위험가중치",
"description": "위험가중치는 금융 자산이나 부채의 위험 정도를 반영하여 부여되는 가중치를 의미합니다. 이는 자본 적정성을 평가하는 데 사용됩니다.",
"example": "예를 들어, 국가채권의 위험가중치는 낮게 설정되고, 신용등급이 낮은 기업채권의 위험가중치는 높게 설정됩니다."
},
{
"term": "RBC비율",
"description": "위험기준자기자본비율(RBC비율)은 보험회사의 자본 적정성을 평가하기 위해 사용되는 비율로, 보유 자본을 위험가중자산으로 나눈 값을 의미합니다.",
"example": "예를 들어, 한 보험회사의 RBC비율이 높다면, 이는 해당 회사의 자본이 충분히 적정하다는 것을 의미합니다."
},
....이후 어떤 방식으로 "환율이 무엇인지 알려줘"와 같은 질문에서 키워드인 환율을 추출할지 고민해보았다. 이를 위해 한국어 형태소 분석기인 Komoran과 TF-IDF 기법을 사용하였다. Komoran 라이브러리를 통해 단어를 추출하여 DB의 경제 용어와 매칭시켜주었는데 정확도를 높이기 위해 문장 혹은 문서 내의 단어의 중요도를 가중치로 측정하는 기법인 TF-IDF를 사용하였다.
public List<String> doWordNouns(String text) throws Exception {
logger.info("{}.doWordAnalysis Start !", this.getClass().getName());
logger.info("분석할 문장 : {}", text);
// 분석할 문장에 대해 정제(쓸데없는 특수문자 제거)
String replace_text = text.replace("[^가-힣a-zA-Z0-9]", " ");
logger.info("한국어, 영어, 숫자 제외 단어 모두 한 칸으로 변환시킨 문장 : {}", replace_text);
// 분석할 문장의 앞, 뒤에 존재할 수 있는 필요없는 공백 제거
String trim_text = replace_text.trim();
logger.info("분석할 문장 앞, 뒤에 존재할 수 있는 필요 없는 공백 제거 : {}", trim_text);
// 형태소 분석 시작
KomoranResult analyzeResultList = this.nlp.analyze(trim_text);
// 형태소 분석 결과 중 명사만 가져오기
List<String> rList = analyzeResultList.getNouns();
if (rList == null) {
rList = new ArrayList<>();
}
// 분석 결과 확인을 위한 로그 찍기
Iterator<String> it = rList.iterator();
while (it.hasNext()) {
// 추출된 명사
String word = CmmUtil.nvl(it.next());
}
return rList;
}GDP와 같은 영어 단어를 추출하기 위해 정규 표현식을 사용하였다.
public Map<String, Integer> extractEngWords(String question) {
Map<String, Integer> engKeywords = new HashMap<>();
// 정규 표현식을 사용하여 영어 단어를 추출
String[] parts = question.split("[^A-Za-z]+");
for (String part : parts) {
Matcher matcher = ENGLISH_WORD_PATTERN.matcher(part);
while (matcher.find()) {
String word = matcher.group();
System.out.println("word: " + word);
engKeywords.put(word, engKeywords.getOrDefault(word, 0) + 1);
}
}
System.out.println("engKeywords: " + engKeywords);
return engKeywords;
}그러나... 질문 내에서 단어를 너무 잘 찾는 나머지 "본원소득이 뭐야?"라는 질문에 대하여 '본원', '소득'을 추출해 '소득'에 대한 설명을 응답하는 문제점이 있었다. brute force를 활용하여 결합된 명사를 먼저 DB 내에서 매칭시키도록 구현하여 해결하였다.
// bruteforce search
private Map<String, String> findTermByCombinedNouns(List<String> combinedNouns, List<EconomicTerm> terms) {
for (EconomicTerm term : terms) {
for (String combinedNoun : combinedNouns) {
if (term.getTerm().equalsIgnoreCase(combinedNoun)) {
return createResponse(term);
}
}
}
return null;
}
두 번째로 경단 경제 기사를 읽다가 생긴 궁금증들을 챗봇에서 해결하고자 하는 경우를 대처하였다. 우선, 사용자가 최근에 읽은 기사 3개 중 도움을 받고자 하는 기사를 클릭한 뒤 기사 내용에 대해 질문하도록 프론트 쪽에서 설계하였다. 이후 해당 기사 정보와 질문 내용을 GPT 라이브러리를 통해 해결하였는데, 이는 GPT의 기능에 지나치게 의존하여 해결한 방법이기에 다른 차별화된 해결 방법이 있을지 고민해 보았다.
이전에 기사 재생성을 할 때와 마찬가지로 RAG를 활용하면 관련된 최신 기사 내용을 담아낼 수 있어 답변의 품질이 더욱 높일 수 있었다! 예를 들어 최근 크게 이슈화된 2024년 7월 13일에 발생한 트럼프 암살 미수 사건에 관한 기사가 경단 뉴스레터에 업로드되었고 범인에 대한 신상이 아직 밝혀지지 않은 상황이기에 해당 기사에 범인의 신상에 대한 정보가 담겨 있지 않은 상황에서 사용자는 이후에 범인이 누군지 왜 그런 범행을 했는지에 대해 궁금할 수 있다. 이때 챗봇을 통해 질문하게 된다면 RAG를 활용하여 범인에 대한 신상이 공개되었는지 최신 기사들을 살펴본 뒤 답변할 수 있을 것이다. 이 방법은 최신 정보에 취약한 GPT의 한계를 보완한 점에서도 큰 이점이 있다.
async def request_rag_applied_openai(
news_id: int, system_prompt: str, session: AsyncSession
) -> Dict:
openai_api_key = os.getenv("OPENAI_API_KEY")
google_api_key = os.getenv("GOOGLE_API_KEY")
google_cse_id = os.getenv("GOOGLE_CSE_ID")
search = AsyncGoogleSearchAPIWrapper(api_key=google_api_key, cse_id=google_cse_id)
google_cse_retriever = GoogleCSERetriever(
api_key=google_api_key, cse_id=google_cse_id
)
# Step 0 : 기사 id값에 따른 기사 원문 가져오기
article_service = ArticleManageService()
article_by_id = await article_service.get_article_by_id(news_id, session)
original_text = article_by_id.content
if not original_text:
raise HTTPException(status_code=404, detail="Article not found.")
# Step 1: Google Custom Search API를 사용하여 사용자가 입력한 original_text 관련 정보 전부 수집
# original_text와 관련된 웹 페이지의 목록을 반환함. 각 웹 페이지는 title(검색 결과 제목), link(웹 페이지 url), snippet(검색 결과의 요약)으로 구성됨.
google_results = await google_cse_retriever.retrieve(original_text)
logger.info(f"1. Google results: {google_results}")
if not original_text:
response = await openai_response(openai_api_key, system_prompt)
return RagAppliedResult(
result_text=response.generations[0][0].text,
related_documents=[],
).to_dict()
# Step 2: 검색 결과를 벡터화하고 ChromaDB에 저장
chroma_db_manager = ChromaDBManager()
await chroma_db_manager.add_documents(google_results)
# Step 3: 저장된 문서 중에서 사용자 쿼리와 유사한 문서 검색, AsyncGoogleSearchAPIWrapper를 사용하여 추가 정보 수집
search_results = await chroma_db_manager.search_documents(
original_text
) # 벡터 유사도 검색 수행
logger.info(f"3. Search results: {search_results}")
additional_info = await search.aget_relevant_documents(original_text, num_results=3)
logger.info(f"3. Additional info: {additional_info}")
# Step 4: 프롬프트 생성 (원문 + 검색 결과 + 추가 정보)
rag_applied_prompt = await create_rag_applied_prompt(
original_prompt=system_prompt,
relevant_info=search_results + additional_info,
original_text=original_text,
)
# Step 5: OpenAI 요청 결과 반환
response = await openai_response(openai_api_key, rag_applied_prompt)
logger.info(f"최종 Response: {response}")
return RagAppliedResult(
result_text=response.generations[0][0].text,
related_documents=search_results + additional_info,
).to_dict()
세 번째로 경단 플랫폼을 사용하는 데 어려움이 있는 경우를 대비하고자 자주 묻는 질문들과 경단 소개 페이지를 참고하도록 설계하였다. 다음에 사용자의 질문 또한 DB에 저장한 뒤 관리자 페이지에서 답변 후 자주 묻는 질문에 추가하는 방식으로 답변할 수 있다.

(3) 조회 API
팀장과 나를 제외하고는 스프링에 대한 경험이 없었기에 스프링을 통한 조회 API 또한 직접 구현하였다. 사용자별로 최근 본 기사 조회하는 API, 기사 상세 조회 API 및 조회수 저장하는 로직, 기사별 조회수를 기반으로 금주 가장 인기 있는 기사 10개 조회하는 API 등 조회 관련 API 구현을 도맡았다. 카테캠과 김영한 강사님 강의의 효과가 있었던 것인지 나름 완벽하지는 않더라도 RESTful하게 짤 수 있었다! 프론트엔드 팀원을 위해 API 명세서 또한 작성해 주었다.
// 최근 조회한 기사 3개 가져오는 메서드
public List<Article> getRecentViewedArticles(Long userId) {
userManageService.checkUserExist(userId);
List<ArticleViewHistory> recentViewedHistories = articleViewHistoryJpaRepository.findTop100ByUserIdOrderByViewedAtDesc(
userId);
return recentViewedHistories.stream()
.map(ArticleViewHistory::getArticle)
.distinct()
.limit(3)
.collect(Collectors.toList());
} // 금주 가장 인기 있는 기사 10개 가져오는 메서드 (조회수 기준)
public List<PopularArticleResponse> getPopularArticles() {
// 오늘을 기준으로 이번 주의 시작과 끝을 구함 (월요일부터 일요일까지)
LocalDate today = LocalDate.now();
LocalDateTime mondayDateTime = today.with(DayOfWeek.MONDAY).atStartOfDay();
LocalDateTime sundayDateTime = today.with(DayOfWeek.SUNDAY).plusDays(1).atStartOfDay();
List<Article> articles = articleJpaRepository.findTop10ByPublishedAtBetweenAndIsValidTrueOrderByViewCountDesc(mondayDateTime, sundayDateTime);
return articles.stream()
.map(article -> new PopularArticleResponse(article.getId(), article.getSimpleTitle(), article.getViewCount()))
.collect(Collectors.toList());
}
3. 길고 길었던 프로젝트 후기

대략 한 달간의 시간 동안 매일 끊임없는 구현과 리팩토링의 반복이었다. 혼자 하는 개인 프로젝트가 아니고 대회 마감 기한이 있었기에 매일 새벽 4시~5시까지 개발하며 일출을 보고 잠자리에 들었다. 또한 뉴닉, 어피티, 매일경제, 한국경제와 같이 기존의 플랫폼과 어떤 차별점을 가져야 할지에 대해 깊이 생각하며 아이디어를 머릿속에서 쥐어짤 때는 개발이 제일 쉽겠다는 생각이 들기도 하였다. 덕분에 하드스킬뿐만 아니라 소프트 스킬도 성장시킬 수 있었다. (기획을 정말 만만하게 보면 안 된다. ㅜㅜ) 디자인 또한 우리가 직접 구상하느라 시간이 꽤 지체되었다.

팀원들 모두 진지하게 임하며 다 같이 영차영차 열심히 했던 점이 가장 기억에 남고 내게는 소중한 경험이 되었다. 구현한 기능이 많았고 프론트엔드 엔지니어가 팀에 한 명뿐이었기에 최종 산출물을 제출할 때 웹사이트가 100% 완성된 상태는 아니었지만 각자 최선을 다했다는 점에 있어서 큰 박수를 보내고 싶다.
다음에 더 많은 기능과 사용자들의 피드백을 바탕으로 v2를 내는 것이 목표다! (그러나 겨울방학쯤에 할 수 있지 않을까 싶다.!)
나의 첫 프로젝트를 성공적으로 마무리했다는 안도감과 이 정도로 진지하게 개발에 임했던 적이 있을까…. 싶은 경외감이 맞물리는 상황에서 이전까지는 다소 확실히 와닿지 못한 성장했다는 확신에 행복하다.
'성장 및 회고' 카테고리의 다른 글
| 2학년 2학기, 배움의 기록 (0) | 2025.01.06 |
|---|---|
| [카테캠 2기] 아이디어톤 우수상 후기 (0) | 2024.08.25 |
1. 근황
2024년 4월 10일, 전역 후 후련할 것만 같았던 마음은 좀처럼 편하지 못했다. 🥲 1년 9개월이라는 시간을 군대에서보내는 동안안 정말 많은 것이 눈에 띄게 바뀌었다! 챗GPT의 등장, 저출산, 경기 침체, 친구들의 취직등등…. 비록록 대학교 2학년이라는 시기가 취업과 장래를 생각하기에는 이른 시기라고 생각하곤 했지만, 그렇다고 무턱대고 놀기에는 나의 20대가가 너무 아깝다는 생각이 들었다. 🔥🔥 (카뮈의 철학이 머릿속에 떠오르던 시기였다!!)
'뭐라도 해보자! 좋아하는 일, 하고 싶은 일을 하염없이 찾기보다 당장 뭐라도 해보는 거야!' 20대의 가장 큰 자산은 '경험'이라는 생각으로 살던 저는 본격적으로 뭐라도 해보기 시작했다. 그러던 와중 컴퓨터공학과에 재학 중인 나는 당시 스타트업에서 인턴 생활을 하는 여자 친구의 영향으로 개발에 큰 관심을 가지게 된다. 당시 4월부터 시작하는 카카오에서 운영하는 부트캠프인 카카오테크 캠퍼스에 BE 트랙으로 지원하여 합격한 상태이기에 시작이 좋았다!
우선 대략 2달 동안 '할 수 있는 것들'에 매진하였다. 카테캠(카카오테크 캠퍼스) 강의를 꾸준히 들으며 복습을 게을리하지 않았고, 1학년 때부터 재미를 붙인 알고리즘을 꾸준히 풀며 블로그에 풀이를 올렸다. 또한 동아리를 통해 'Spring 입문초록스터디'에 참여하였으며 부족한 부분은 인프런의의 김영한 강사님 강의로 채워나갔다. 꾸준히 공부하는 것이 지겹고 싫다기보다는 내가 할 수 있는 것들을 하면서성장해 나가는는 내 모습이 되게 재밌었다! RPG 게임처럼 명확한 레벨은 보이지 않지만 적어도 어제와 오늘의 나는 정말 다르다는 것을 매일 느끼며 큰 보람을 느꼈다. 특히 여자 친구와와 학교 선배님을 만나며 공부하며 궁금했던 것을 물어보고 부족했던 내용을 채우는 과정에서 한 달 전, 아니 일주일 전만 해도 무지했던 내용들이 머릿속에서 정리되는 경험이 내겐 큰 성취감이자 꾸준히 할 수 있게 해준 원동력이었다.
2달이 지나고 6월 초쯤 되니 내가 배웠던 내용들을 직접 구현해보고 싶었다. 나와 같은 마음을 가진 4명(같은 학번 친구 2명 + 여자친구와 여자친구의 친구)과 함께 팀을 꾸려 '경단' 프로젝트를 진행하게 된다. 처음엔 우리끼리 재밌는 주제의 토이 프로젝트를 만들어보자는 생각이었지만 목표가 있으면 좋을 거 같아 지원했던 '2024년 SW 중심대학 디지털 경진대회'의 SW부문에 우리 프로젝트 기획서가 채택되어 학교 대표팀으로 참가하게 되었다. 간단한 토이 프로젝트로 끝날줄 알았는데 갑작스러운 기회에 걱정되긴 했다. 왜냐하면 나와 내 친구 2명은 스타트업에서 6개월동안 인턴을 한 여자친구에 비하면 개발 경험이나 프로젝트 경험이 암담한 수준이었기 때문이다. 그래도 하고자 하면 무엇이든 이루어 낼 수 있을 거라는 마음으로 프로젝트에 임하게 된다!!
2. 경단 프로젝트 팀원으로서의 내가 한 일들
개발 경험과 프로젝트 경험이 부족했기에 처음엔 팀원으로서 1인분을 할 수 있을지 걱정되었다. 그러나 누구에게나 처음이 있고 내게 이 처음은 가장 값진 것이었으면 좋겠다는 생각 들었다. 우선, 전역 직후 나의 모습과 마찬가지로 '할 수 있는 것들'에 매진하였다.
경단 프로젝트의 배경은 '경제를 단순하게'라는 슬로건을 걸고 청년들의 경제적 취약점을 보완하여 경제 문맹률을 낮추자는 것이다. 성인이 되고 본격적인 경제생활을 시작하게 된다. 하지만 아래 기사 자료에서도 볼 수 있듯이 학창 시절 경제는 필수과목이 아니었기에 대다수는 경제 및 금융 관념에 대해 무지하다.
사탐에 경제 과목이 있다 한들 어려운 난이도에 응시율도 낮고 공통 과목 중에서는 경제 관련 수업은 통합사회의 '경제 및 금융' 단원뿐이다.
좋아! 청년들의 경제 문맹을 퇴치하는 것은 좋은데 어떤 방법으로…?? 필자는 군복무 시절부터 '어피티'라는 뉴스레터 사이트를 애용하였다. 최신 소식을 쉽게 설명해 주고 어려운 경제 용어 또한 따로 정리해 주기에 전문가가 아닌 나 또한 자연스럽게 경제 이슈에 큰 관심을 가지게 되었고, 국가 공인 경제 자격증인 '매경테스트'와 'TESAT'도 딸 정도로 흥미가 생겼다.
내게 직접적으로 도움이 된 '어피티'에서 영감을 받아 생성형 AI를 활용하여 어려운 경제 기사를 쉽게 설명하면 좋겠다는 생각이 들었다. 팀원들과 주에 3~4번 비대면 혹은 대면으로 만나서 기획하며 경제 기사 플랫폼을 만들기로 결정하였다. 아래 보이는 것처럼 크게 5가지 기능을 기획하였는데, 그중에서 난 어려운 경제 기사를 재생성과 챗봇, 그리고 조회 API를 담당하였다.
(1) 어려운 경제를 쉬운 기사로 재생성하기
어피티나 뉴닉과 같이 경제 전문가가 아니더라도 읽기 쉬운 뉴스레터들이 있지만 매일경제, 한국경제는 상대적으로 경제 관련 지식이 부족하면 읽기 힘든 부분이 있다. 그렇지만 매일경제와 한국경제는 어피티나 뉴닉보다 최신 이슈에 관해서 더욱 다방면으로 다루고 기사 업로드 속도 또한 훨씬 빠르다. 따라서 장점들만 뽑아 매일경제, 한국경제의 최신 경제 기사를 어피티, 뉴닉과 같이 쉬운 기사로 재생성하는 것이 우리의 목표였다.
우선 FASTAPI를 활용하여 pipenv 기반 환경에서 파이썬 웹스크래핑 라이브러리 'beautiful soup4'를 활용하여 기사 제목, 내용, 이미지를 스크래핑하였다. 그 후 open ai의 gpt-4o 모델을 활용하여 쉬운 기사로 재생성하였다.
async def crawl_article(self, news_type: str, url: str) -> ArticleResponse:
news_type = find_publisher(news_type)
# 웹 페이지 가져오기
try:
response_text = await self.__fetch_page(url)
except aiohttp.ClientError as e:
raise HTTPException(
status_code=400, detail=f"Error fetching the URL: {str(e)}"
) from e
result_html = BeautifulSoup(response_text, "html.parser")
title = self.__find_title(result_html, news_type)
pub_date = self.__find_pub_date(result_html, news_type)
image_url = self.__find_image(result_html, news_type)
if news_type == Publisher.SEOUL_KYUNG:
content = self.__find_content_from_script(result_html)
else:
main_section = self.__find_main_section(result_html, news_type)
content = self.__find_content_from_main_section(main_section, news_type)
if not content.strip():
raise HTTPException(status_code=404, detail="파싱 결과가 없습니다.")
return ArticleResponse(title=title, content=content, pub_date=pub_date, image_url=image_url)
웹 스크래핑의 경우 1학년 때 '노마드코더의 python으로 웹 스크래퍼 만들기' 강의를 수강하고 코로나 확진자 수, 신규 확진자 수 등을 불러와 파일에 저장하는 토이 프로젝트를 홀로 진행한 적이 있었기에 어렵지 않게 구현할 수 있었다. (1학년 때 한 웹 스캐래핑 토이 프로젝트)
gpt를 활용하는 것 또한 open ai playgorund의 API reference에 자세히 정리되어 있어 프롬프팅 엔지니어링 또한 어렵지 않게 구현하였다.
너는 내가 제공하는 어려운 대한민국 경제 신문 본문을 20대 초반이 읽어도 이해하기 쉽게, 한국어로 기사를 재생성하는 기자이다.
아래 json 형식에 맞게 기사를 재생성해야 한다. 단, 기사 본문의 경우 문단을 나누어야 한다.
다음은 json 형식의 예시이다:
{
"title": "기사 제목(한국어)",
"content": "기사 본문 (한국어)",
"phrase": ["어려웠던 경제 표현들" : "어려웠던 경제 표현들을 쉽게 바꾼 문구"] (문자열 리스트) 예를 들어 "환율" : "다른 나라 돈과 우리나라 돈을 교환하는 비율"과 같이,
"comment": "기사를 3줄 이하로 요약하기. 단, 친근하게. (한국어)",
"category": "기사가 어느 카테고리, 즉 enum에 속하는지 (한국어)"
}
enum Category:
ECONOMY_AND_BUSINESS = "경제 및 기업"
POLITICS_AND_SOCIETY = "정치 및 사회"
TECHNOLOGY_AND_CULTURE = "기술 및 문화"
SPORTS_AND_LEISURE = "스포츠 및 여가"
OPINION_AND_ANALYSIS = "오피니언 및 분석"
이후 팀장인 여자친구가 gpt에만 의존하지 않기 위해 RAG / LangChain을 활용하여 재생성하려는 기사와 연관된 내용의 다른 기사들을 불러와 기술적 차별화를 이루었고 매일 오전 5시에 기사를 스크래핑해오는, 스케쥴링 또한 구현하였다.
(2) 대화형 인터페이스 - 챗봇
경단을 이용하며 생긴 궁금증들을 다른 웹사이트를 통해 해결하는 것이 아닌 경단 내에서 해결하는 것이 충성 고객 유치와 사용자들의 편의에 있어서 큰 도움이 될 거 같아 대화형 인터페이스인 챗봇을 구현하기로 하였다. 앞서 구현했던 쉬운 기사 재생성과 달리 챗봇 관련 API 모두를 스프링 환경에서 혼자 구현해야 했기에 부담이 있었지만 우려와는 달리 멋지게 해낼 수 있었다!
우선, 챗봇을 사용하는 사용자들은 챗봇을 사용하며 어떤 편의를 기대할지 고민해 보았고 크게 3가지로 추렸다.
첫 번째로 경제 용어를 묻는 상황에 대한 대처가 필요할 거 같았다. 나 또한 경제 기사를 읽으며 어려운 경제 용어들을 한국은행의 경제 용어사전에서 직접 찾아보며 학습했던 경험이 있었기 때문이다. 보통 "GDP가 무엇인지 알려줘"와 같은 질문이 챗봇 대화창에 입력될 텐데 사용자의 질문에 대한 응답을 GPT에 의존하여 처리하기에는 기술적 차별점도 부족하였고 무엇보다 GPT 사용료가 너무 아까웠다! 따라서 GPT 없이 사용자의 질문에 대처하기로 하였다.
일단, 한국은행 경제 용어 700선과 기획재정부의 시사 경제 용어사전을 참고하여 경제 용어의 뜻과 예문을 DB에 저장하였다. 그러나 해당 자료들에서 역시 용어 뜻을 풀이하는 데 있어서 어려운 개념이 빈번하게 사용되었기에 사용자의 이해를 돕고자 용어 뜻과 예문을, GPT를 활용하여 프롬프팅한 뒤에, DB에 저장하였다. 이 과정에서 경제 용어 뜻과 예문을 일일이 DB에 저장하는 것은 무리였기에 JSON 파일에 전부 담은 후 파싱하여 DB에 손쉽게 DB에 저장할 수 있었다. 응답해 주는 과정에서 exception을 방지하고자 단어의 중복 검사 또한 진행해 주었다. 이를 통해 대략 900개가 넘는 경제 용어를 DB에 저장하였다.
{
"term": "STRIPS",
"description": "원금이자분리채권(STRIPS)은 채권의 원금과 이자를 분리하여 각각 개별적인 제로 쿠폰 채권으로 거래하는 금융 상품을 의미합니다.",
"example": "예를 들어, 한 채권의 원금 부분과 이자 부분을 따로 분리하여 각각 거래할 수 있습니다."
},
{
"term": "원금이자분리채권",
"description": "원금이자분리채권(STRIPS)은 채권의 원금과 이자를 분리하여 각각 개별적인 제로 쿠폰 채권으로 거래하는 금융 상품을 의미합니다.",
"example": "예를 들어, 한 채권의 원금 부분과 이자 부분을 따로 분리하여 각각 거래할 수 있습니다."
},
{
"term": "위험가중자산",
"description": "위험가중자산은 은행이 보유한 자산 중에서 위험도를 반영하여 가중치를 부여한 자산을 의미합니다. 이는 자본 적정성을 평가하는 데 사용됩니다.",
"example": "예를 들어, 주택담보대출은 상대적으로 낮은 가중치를 가지지만, 무담보 대출은 높은 가중치를 가질 수 있습니다."
},
{
"term": "위험가중치",
"description": "위험가중치는 금융 자산이나 부채의 위험 정도를 반영하여 부여되는 가중치를 의미합니다. 이는 자본 적정성을 평가하는 데 사용됩니다.",
"example": "예를 들어, 국가채권의 위험가중치는 낮게 설정되고, 신용등급이 낮은 기업채권의 위험가중치는 높게 설정됩니다."
},
{
"term": "RBC비율",
"description": "위험기준자기자본비율(RBC비율)은 보험회사의 자본 적정성을 평가하기 위해 사용되는 비율로, 보유 자본을 위험가중자산으로 나눈 값을 의미합니다.",
"example": "예를 들어, 한 보험회사의 RBC비율이 높다면, 이는 해당 회사의 자본이 충분히 적정하다는 것을 의미합니다."
},
....이후 어떤 방식으로 "환율이 무엇인지 알려줘"와 같은 질문에서 키워드인 환율을 추출할지 고민해보았다. 이를 위해 한국어 형태소 분석기인 Komoran과 TF-IDF 기법을 사용하였다. Komoran 라이브러리를 통해 단어를 추출하여 DB의 경제 용어와 매칭시켜주었는데 정확도를 높이기 위해 문장 혹은 문서 내의 단어의 중요도를 가중치로 측정하는 기법인 TF-IDF를 사용하였다.
public List<String> doWordNouns(String text) throws Exception {
logger.info("{}.doWordAnalysis Start !", this.getClass().getName());
logger.info("분석할 문장 : {}", text);
// 분석할 문장에 대해 정제(쓸데없는 특수문자 제거)
String replace_text = text.replace("[^가-힣a-zA-Z0-9]", " ");
logger.info("한국어, 영어, 숫자 제외 단어 모두 한 칸으로 변환시킨 문장 : {}", replace_text);
// 분석할 문장의 앞, 뒤에 존재할 수 있는 필요없는 공백 제거
String trim_text = replace_text.trim();
logger.info("분석할 문장 앞, 뒤에 존재할 수 있는 필요 없는 공백 제거 : {}", trim_text);
// 형태소 분석 시작
KomoranResult analyzeResultList = this.nlp.analyze(trim_text);
// 형태소 분석 결과 중 명사만 가져오기
List<String> rList = analyzeResultList.getNouns();
if (rList == null) {
rList = new ArrayList<>();
}
// 분석 결과 확인을 위한 로그 찍기
Iterator<String> it = rList.iterator();
while (it.hasNext()) {
// 추출된 명사
String word = CmmUtil.nvl(it.next());
}
return rList;
}GDP와 같은 영어 단어를 추출하기 위해 정규 표현식을 사용하였다.
public Map<String, Integer> extractEngWords(String question) {
Map<String, Integer> engKeywords = new HashMap<>();
// 정규 표현식을 사용하여 영어 단어를 추출
String[] parts = question.split("[^A-Za-z]+");
for (String part : parts) {
Matcher matcher = ENGLISH_WORD_PATTERN.matcher(part);
while (matcher.find()) {
String word = matcher.group();
System.out.println("word: " + word);
engKeywords.put(word, engKeywords.getOrDefault(word, 0) + 1);
}
}
System.out.println("engKeywords: " + engKeywords);
return engKeywords;
}그러나... 질문 내에서 단어를 너무 잘 찾는 나머지 "본원소득이 뭐야?"라는 질문에 대하여 '본원', '소득'을 추출해 '소득'에 대한 설명을 응답하는 문제점이 있었다. brute force를 활용하여 결합된 명사를 먼저 DB 내에서 매칭시키도록 구현하여 해결하였다.
// bruteforce search
private Map<String, String> findTermByCombinedNouns(List<String> combinedNouns, List<EconomicTerm> terms) {
for (EconomicTerm term : terms) {
for (String combinedNoun : combinedNouns) {
if (term.getTerm().equalsIgnoreCase(combinedNoun)) {
return createResponse(term);
}
}
}
return null;
}
두 번째로 경단 경제 기사를 읽다가 생긴 궁금증들을 챗봇에서 해결하고자 하는 경우를 대처하였다. 우선, 사용자가 최근에 읽은 기사 3개 중 도움을 받고자 하는 기사를 클릭한 뒤 기사 내용에 대해 질문하도록 프론트 쪽에서 설계하였다. 이후 해당 기사 정보와 질문 내용을 GPT 라이브러리를 통해 해결하였는데, 이는 GPT의 기능에 지나치게 의존하여 해결한 방법이기에 다른 차별화된 해결 방법이 있을지 고민해 보았다.
이전에 기사 재생성을 할 때와 마찬가지로 RAG를 활용하면 관련된 최신 기사 내용을 담아낼 수 있어 답변의 품질이 더욱 높일 수 있었다! 예를 들어 최근 크게 이슈화된 2024년 7월 13일에 발생한 트럼프 암살 미수 사건에 관한 기사가 경단 뉴스레터에 업로드되었고 범인에 대한 신상이 아직 밝혀지지 않은 상황이기에 해당 기사에 범인의 신상에 대한 정보가 담겨 있지 않은 상황에서 사용자는 이후에 범인이 누군지 왜 그런 범행을 했는지에 대해 궁금할 수 있다. 이때 챗봇을 통해 질문하게 된다면 RAG를 활용하여 범인에 대한 신상이 공개되었는지 최신 기사들을 살펴본 뒤 답변할 수 있을 것이다. 이 방법은 최신 정보에 취약한 GPT의 한계를 보완한 점에서도 큰 이점이 있다.
async def request_rag_applied_openai(
news_id: int, system_prompt: str, session: AsyncSession
) -> Dict:
openai_api_key = os.getenv("OPENAI_API_KEY")
google_api_key = os.getenv("GOOGLE_API_KEY")
google_cse_id = os.getenv("GOOGLE_CSE_ID")
search = AsyncGoogleSearchAPIWrapper(api_key=google_api_key, cse_id=google_cse_id)
google_cse_retriever = GoogleCSERetriever(
api_key=google_api_key, cse_id=google_cse_id
)
# Step 0 : 기사 id값에 따른 기사 원문 가져오기
article_service = ArticleManageService()
article_by_id = await article_service.get_article_by_id(news_id, session)
original_text = article_by_id.content
if not original_text:
raise HTTPException(status_code=404, detail="Article not found.")
# Step 1: Google Custom Search API를 사용하여 사용자가 입력한 original_text 관련 정보 전부 수집
# original_text와 관련된 웹 페이지의 목록을 반환함. 각 웹 페이지는 title(검색 결과 제목), link(웹 페이지 url), snippet(검색 결과의 요약)으로 구성됨.
google_results = await google_cse_retriever.retrieve(original_text)
logger.info(f"1. Google results: {google_results}")
if not original_text:
response = await openai_response(openai_api_key, system_prompt)
return RagAppliedResult(
result_text=response.generations[0][0].text,
related_documents=[],
).to_dict()
# Step 2: 검색 결과를 벡터화하고 ChromaDB에 저장
chroma_db_manager = ChromaDBManager()
await chroma_db_manager.add_documents(google_results)
# Step 3: 저장된 문서 중에서 사용자 쿼리와 유사한 문서 검색, AsyncGoogleSearchAPIWrapper를 사용하여 추가 정보 수집
search_results = await chroma_db_manager.search_documents(
original_text
) # 벡터 유사도 검색 수행
logger.info(f"3. Search results: {search_results}")
additional_info = await search.aget_relevant_documents(original_text, num_results=3)
logger.info(f"3. Additional info: {additional_info}")
# Step 4: 프롬프트 생성 (원문 + 검색 결과 + 추가 정보)
rag_applied_prompt = await create_rag_applied_prompt(
original_prompt=system_prompt,
relevant_info=search_results + additional_info,
original_text=original_text,
)
# Step 5: OpenAI 요청 결과 반환
response = await openai_response(openai_api_key, rag_applied_prompt)
logger.info(f"최종 Response: {response}")
return RagAppliedResult(
result_text=response.generations[0][0].text,
related_documents=search_results + additional_info,
).to_dict()
세 번째로 경단 플랫폼을 사용하는 데 어려움이 있는 경우를 대비하고자 자주 묻는 질문들과 경단 소개 페이지를 참고하도록 설계하였다. 다음에 사용자의 질문 또한 DB에 저장한 뒤 관리자 페이지에서 답변 후 자주 묻는 질문에 추가하는 방식으로 답변할 수 있다.
(3) 조회 API
팀장과 나를 제외하고는 스프링에 대한 경험이 없었기에 스프링을 통한 조회 API 또한 직접 구현하였다. 사용자별로 최근 본 기사 조회하는 API, 기사 상세 조회 API 및 조회수 저장하는 로직, 기사별 조회수를 기반으로 금주 가장 인기 있는 기사 10개 조회하는 API 등 조회 관련 API 구현을 도맡았다. 카테캠과 김영한 강사님 강의의 효과가 있었던 것인지 나름 완벽하지는 않더라도 RESTful하게 짤 수 있었다! 프론트엔드 팀원을 위해 API 명세서 또한 작성해 주었다.
// 최근 조회한 기사 3개 가져오는 메서드
public List<Article> getRecentViewedArticles(Long userId) {
userManageService.checkUserExist(userId);
List<ArticleViewHistory> recentViewedHistories = articleViewHistoryJpaRepository.findTop100ByUserIdOrderByViewedAtDesc(
userId);
return recentViewedHistories.stream()
.map(ArticleViewHistory::getArticle)
.distinct()
.limit(3)
.collect(Collectors.toList());
} // 금주 가장 인기 있는 기사 10개 가져오는 메서드 (조회수 기준)
public List<PopularArticleResponse> getPopularArticles() {
// 오늘을 기준으로 이번 주의 시작과 끝을 구함 (월요일부터 일요일까지)
LocalDate today = LocalDate.now();
LocalDateTime mondayDateTime = today.with(DayOfWeek.MONDAY).atStartOfDay();
LocalDateTime sundayDateTime = today.with(DayOfWeek.SUNDAY).plusDays(1).atStartOfDay();
List<Article> articles = articleJpaRepository.findTop10ByPublishedAtBetweenAndIsValidTrueOrderByViewCountDesc(mondayDateTime, sundayDateTime);
return articles.stream()
.map(article -> new PopularArticleResponse(article.getId(), article.getSimpleTitle(), article.getViewCount()))
.collect(Collectors.toList());
}3. 길고 길었던 프로젝트 후기
대략 한 달간의 시간 동안 매일 끊임없는 구현과 리팩토링의 반복이었다. 혼자 하는 개인 프로젝트가 아니고 대회 마감 기한이 있었기에 매일 새벽 4시~5시까지 개발하며 일출을 보고 잠자리에 들었다. 또한 뉴닉, 어피티, 매일경제, 한국경제와 같이 기존의 플랫폼과 어떤 차별점을 가져야 할지에 대해 깊이 생각하며 아이디어를 머릿속에서 쥐어짤 때는 개발이 제일 쉽겠다는 생각이 들기도 하였다. 덕분에 하드스킬뿐만 아니라 소프트 스킬도 성장시킬 수 있었다. (기획을 정말 만만하게 보면 안 된다. ㅜㅜ) 디자인 또한 우리가 직접 구상하느라 시간이 꽤 지체되었다.
팀원들 모두 진지하게 임하며 다 같이 영차영차 열심히 했던 점이 가장 기억에 남고 내게는 소중한 경험이 되었다. 구현한 기능이 많았고 프론트엔드 엔지니어가 팀에 한 명뿐이었기에 최종 산출물을 제출할 때 웹사이트가 100% 완성된 상태는 아니었지만 각자 최선을 다했다는 점에 있어서 큰 박수를 보내고 싶다.
다음에 더 많은 기능과 사용자들의 피드백을 바탕으로 v2를 내는 것이 목표다! (그러나 겨울방학쯤에 할 수 있지 않을까 싶다.!)
나의 첫 프로젝트를 성공적으로 마무리했다는 안도감과 이 정도로 진지하게 개발에 임했던 적이 있을까…. 싶은 경외감이 맞물리는 상황에서 이전까지는 다소 확실히 와닿지 못한 성장했다는 확신에 행복하다.
'성장 및 회고' 카테고리의 다른 글
| 2학년 2학기, 배움의 기록 (0) | 2025.01.06 |
|---|---|
| [카테캠 2기] 아이디어톤 우수상 후기 (0) | 2024.08.25 |